Как мы переводим статьи
TLDR
25 статей официальной документации Anthropic переведены на русский с помощью пайплайна из трёх AI-агентов: один пишет, второй проверяет на ту же модель (быстрый surface-check), третий проверяет на другую модель (глубокий semantic-check, защита от same-model bias). Каждый агент работает изолированно, общается отчётами в фиксированном формате. Перевод считается готовым, когда surface-validator говорит PASS, а deep-validator не нашёл high-issues.
Стек: Claude Code subagents с разными моделями
(model: opus для writer и surface-validator,
model: sonnet для deep-validator), фиксированный
глоссарий, thinking=off и temperature=0.
Никакого RAG, никакого fine-tuning — только промпт-инжиниринг и
дисциплина в правилах.
Архитектура (как это работает сейчас)
Три subagent'а в .claude/agents/ + одна slash-команда
в .claude/commands/ + три журнала в
personal/. Всё локально в проекте, никаких внешних
сервисов.
┌─────────────────────────┐
│ Основной Claude (Opus) │
│ — оркестратор в чате │
└────────────┬────────────┘
│ Task()
▼
┌─────────────────────────┐
│ faithful-translator │
│ (Opus, thinking=off, │
│ temperature=0) │
│ → publish/docs/X.html │
└────────────┬────────────┘
│
▼
┌─────────────────────────┐
│ translation-validator │
│ (Opus) │
│ inventory + glossary │
│ + spot-check 5 абзацев │
│ → PASS / FAIL / REVIEW │
└────────────┬────────────┘
│ если PASS
▼
┌─────────────────────────┐
│ deep-validator-sonnet │
│ (Sonnet) │
│ │
│ Phase A: structural │
│ Phase B: image │
│ Phase C: sentence diff │
│ │
│ → log-sonnet.md (auto) │
└─────────────────────────┘
Почему именно три агента:
- writer делает работу — пишет перевод;
- surface-validator ловит явные ошибки быстро (inventory mismatch, glossary, фабрикации в spot-абзацах) — на той же модели, потому что цель не «найти всё», а «отсеять очевидное за низкую стоимость»;
- deep-validator ловит тонкие смысловые сдвиги — на другой модели, потому что та же модель имеет общие blind spots с writer'ом и пропустит свои же ошибки.
Это паттерн evaluator-optimizer из инженерного блога Anthropic — про него подробнее в секции «Теория» ниже.
Easy to start: одна команда
Если хочется просто запустить и посмотреть что получится:
- Открыть Claude Code в этом репозитории.
- Переключить модель:
/model claude-sonnet-4-6(для deep-validation; перевод делает Opus, валидация на той же модели = bias). - Запустить:
/deep-validate --top10.
Slash-команда сама пройдётся по 10 priority статьям, для каждой
запустит deep-validator-sonnet, тот сам обновит журнал
personal/deep-validation-log-sonnet.md. После всех 10
основной Claude вернёт сводную таблицу.
Если хочется добавить новую статью к переводу:
- Прочитать
personal/prompts/source-fetching-cookbook.md(как взять оригинал — не все статьи имеют.mdendpoint). Task(subagent_type="faithful-translator", prompt="...")Task(subagent_type="translation-validator", prompt="...")- Опционально:
/deep-validate <slug>
Это всё. Дальше — для тех, кто хочет понять почему именно так.
Hard to master: теория
Паттерн evaluator-optimizer
Один LLM-вызов генерирует ответ, другой — оценивает и даёт обратную связь. В цикле, пока критерии не выполнены или не достигнут лимит итераций. Идея — итеративное улучшение с независимой оценкой.
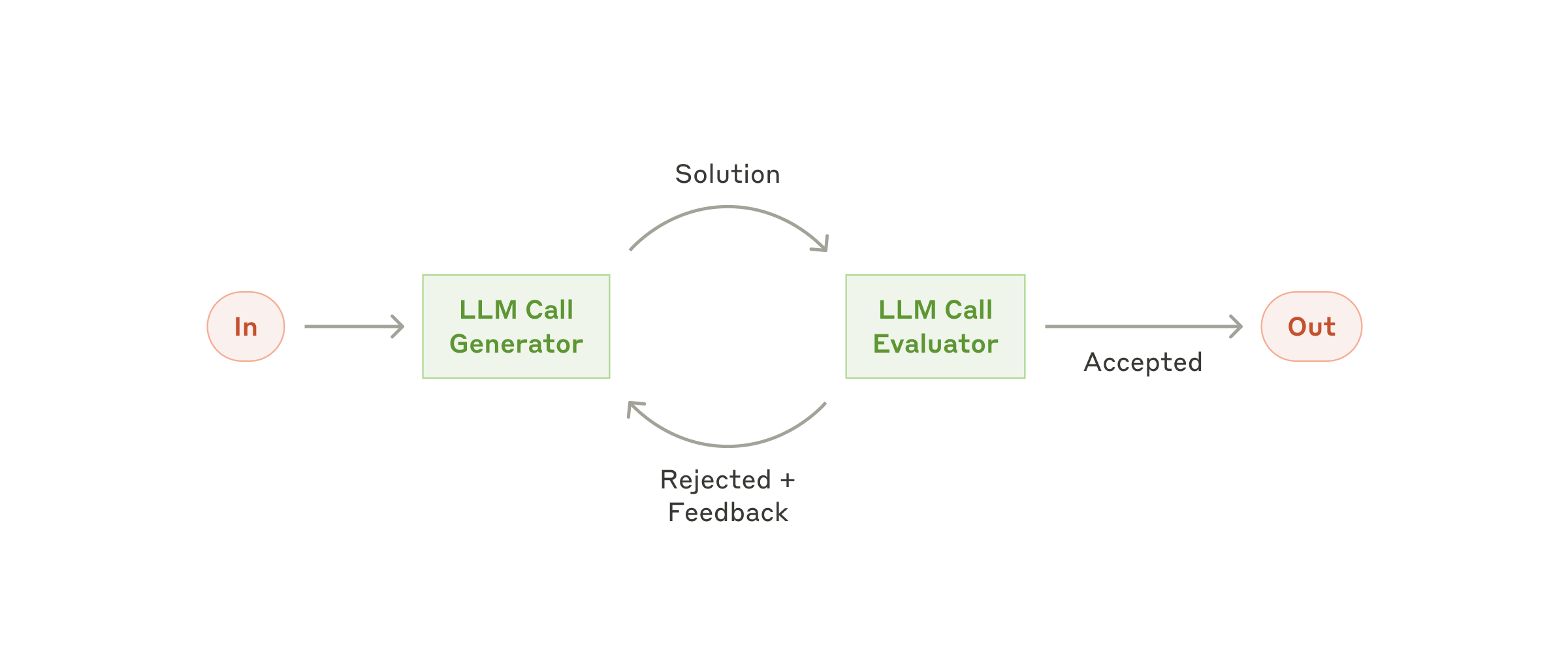
Для перевода это работает потому, что:
- есть чёткие критерии (inventory совпадает, глоссарий соблюдён, числа не выдуманы);
- оценка дешевле генерации (validator не пишет, только сравнивает);
- модель может применить feedback (validator говорит «параграф X пропущен» — writer его дописывает на следующей итерации).
В нашем пайплайне максимум 2 итерации. Если после второй surface-validator всё ещё возвращает FAIL — это не лечится итерацией, нужно править сам промпт writer'а. Дисциплина важнее бесконечного цикла.
Same-model bias и триангуляция
Если writer и validator работают на одной и той же модели, у них общие слепые пятна. Та же модель сделает ту же ошибку и не увидит её при self-check'е. Это известный эффект в LLM-as-a-judge литературе — см. «Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena» (Zheng et al., 2023), раздел про self-preference bias.
Решение — триангуляция: проверять перевод другой моделью. У нас Opus переводит, Sonnet валидирует. Sonnet архитектурно отличается от Opus (меньше параметров, другой training mix), и смысловые сдвиги, которые Opus не замечает в своём же тексте, Sonnet ловит.
Расчёт прост: если на одной статье Sonnet находит 3 medium-issue, которые Opus surface-validator не нашёл, — это и есть та самая «модельная слепота», от которой триангуляция защищает. Цена — один дополнительный прогон ~$0.50 на статью на Sonnet (gross), это оправданно для канонических переводов.
Почему thinking=off и temperature=0
Технически extended thinking (high) даёт модели «больше думать перед ответом». Звучит как улучшение, но для перевода оборачивается катастрофой:
- модель начинает «улучшать» оригинал — перекомпоновывает абзацы, схлопывает collapsible-блоки в один абзац, сокращает примеры кода;
- пропадают числовые детали («примерно 80%» становится просто «снижение значительно»);
- изменяются модальности: «consider these metrics» → «обязательно используйте эти метрики».
Перевод — это задача воспроизведения, не задача решения. Модели нужно как можно меньше «думать» — она уже знает как переводить. Помощь thinking'а тут не нужна.
temperature=0 — той же логике: воспроизводимость и
предсказуемость важнее креативности. Если запустить тот же промпт
дважды, должны получиться одинаковые переводы.
Глоссарий как отдельная инфраструктура
Жёсткий маппинг EN→RU вшит в промпт каждого агента (writer, validator, deep-validator). Несколько десятков терминов с конкретным переводом и обоснованием. Например:
eval / evaluation→ оценка (НЕ «эвалюация»)grading→ проверка (НЕ «грейдинг»)output(s)→ выходные данные (НЕ «выходы»)you→ вы (НЕ «ты»)brainstorm→ мозговой штурм (НЕ «побрейнштормить»)
Глоссарий дублируется между файлами агентов — сознательная техническая избыточность. Каждый файл должен быть самодостаточным, чтобы его можно было использовать вне этого репозитория (в Claude.ai, GPT, Gemini как reference-промпт). Изменение глоссария требует синхронизации в нескольких местах — цена за переносимость.
Faithful translation: «структуру не трогать»
Главный инвариант: сохранять структуру 1:1.
- сколько H2 в оригинале — столько в переводе;
- каждый
<Accordion>/ collapsible / details попадает в<details>перевода; - каждый
<CodeGroup>на N языках попадает в табы с теми же N языками; - числа, дата, имена моделей — буквально 1:1.
Это противоположность того, что обычно делают LLM «по дефолту» — пересказывают своими словами, упрощают, сокращают. Faithful policy в промпте explicitly запрещает: «не упрощай», «не суммаризируй», «не объясняй своими словами», «не добавляй комментарии переводчика».
Как мы к этому пришли (история)
Каждая версия пайплайна — реакция на конкретную проблему. История в порядке появления.
v1 (2026-04-23): первая попытка
Конфигурация: Opus 4.7, extended thinking = high, общий промпт без глоссария, без validator'а.
Результат: на 3 длинных статьях
(building-effective-agents, prompt-caching,
extended-thinking) ~70% контента потеряно.
Все <Accordion> выпали — модель свернула их в
один абзац. Числовые таблицы заменились на «зависит от модели».
Урок: thinking=high несовместим с задачами воспроизведения. Промпт без явного запрета на «улучшения» — модель «улучшает».
v2 (2026-04-24): evaluator-optimizer
Изменения:
thinking=off,temperature=0;- добавлен жёсткий глоссарий в промпт writer'а;
- добавлен translation-validator (тоже Opus, surface-check: inventory + glossary + spot 5 случайных абзацев);
- цикл: writer → validator → если FAIL писатель правит по отчёту → ещё одна валидация → стоп. Максимум 2 итерации.
Результат: 25 статей закрыты PASS базовым циклом. Структурные потери ушли. Числовые ошибки стали редкими. Glossary-нарушения почти не появляются.
v3 (2026-04-26): глубокая независимая валидация
Проблема: на нескольких статьях ручная сверка показала тонкие смысловые сдвиги, которые surface-validator не видел. Например, modal shift «may consider» → «обязательно следует». Технически предложение переведено, но смысл изменён.
Гипотеза: Opus self-checking имеет blind spots — та же модель не видит свои же ошибки.
Изменения:
- добавлен deep-validator-sonnet (Sonnet 4.6, model frontmatter
model: sonnet) — другая модель = независимые blind spots; - 3-фазная проверка: structural inventory diff (Phase A) + image integrity (Phase B) + sentence-by-sentence semantic alignment (Phase C);
- отдельные журналы по моделям:
deep-validation-log-sonnet.mdиdeep-validation-log-opus.md(последний — для триангуляции, если перевод делал не-Opus); - slash-команда
/deep-validate [slug...]для оркестрации; - каждое замечание Sonnet'а сопровождается цитатой оригинала — защита от ложных срабатываний.
v4 (2026-04-26): production-ready инфраструктура
- Сайт переехал в подпапку
publish/для деплоя на Cloudflare Pages —personal/,.claude/,CLAUDE.mdостаются вне публичного доступа; - в
.claude/settings.jsonпрописаны permissions с wildcards — Claude Code не спрашивает разрешения на каждую команду внутри агентов; - пути в агентах обновлены:
publish/docs/<slug>.htmlпервый в порядке поиска,docs/в fallback.
Проблемы LLM, с которыми мы столкнулись
Эта секция — не про форматирование и не про инфраструктуру. Это про фундаментальные особенности работы LLM, которые мы наблюдали и мимо которых пройти не получилось. Большинство из них описаны в академической литературе — даём ссылки.
1. Thinking как давление к «улучшайзингу»
Что наблюдали: Opus 4.7 с
extended thinking = high на длинных переводах
систематически перекомпоновывал оригинал — схлопывал collapsible-
блоки в один абзац, сокращал примеры кода, заменял конкретные
числа на обобщения («примерно 80%» → «значительное снижение»).
На building-effective-agents потерялось ~70% контента.
Объяснение: reasoning model'и обучены оптимизировать качество ответа. На задачах где «качество» = «решение лучше», это работает. Но на задачах воспроизведения — переводе, цитировании, копировании структуры — модель применяет ту же оптимизацию: «улучшает» текст, хотя её об этом не просили. Это не баг, это базовое поведение reasoning models.
Решение: thinking = off,
temperature = 0, плюс explicit-инструкции в системном
промпте: «не упрощай», «не суммаризируй», «не предлагай улучшений».
Модель должна копировать, а не думать.
Урок: для любых задач воспроизведения (faithful translation, document conversion, format-preserving rewrites) — отключайте thinking. И не надейтесь, что модель сама поймёт когда «думать» не нужно.
2. Intrinsic self-correction — фундаментально не работает
Что наблюдали: когда мы добавили
translation-validator на Opus (та же модель что
переводила) — он стабильно возвращал PASS на статьях, в которых
при ручной сверке находились смысловые сдвиги. Просили модель
«найди свои ошибки» — она не находила.
Это известный эффект. Huang et al. 2023, «Large Language Models Cannot Self-Correct Reasoning Yet»: без external feedback модели не могут надёжно улучшать собственные ответы — они либо не видят ошибок, либо «исправляют» правильное на неправильное. Stechly et al. 2024, «On the Self-Verification Limitations of Large Language Models»: даже на простых логических задачах самопроверка ниже chance'а.
Решение: мы добавили cross-model validation — Sonnet проверяет переводы Opus. Другая модель = другие blind spots. Это не «лучше / хуже», это independent. То же — в LLM-as-judge литературе: Zheng et al. 2023 показывают что cross-model judging существенно надёжнее self-judging.
Урок: «попроси модель проверить себя» — это дешёвая иллюзия безопасности. Если важна корректность — нужна независимая проверка: другая модель, человек, или deterministic-тест.
3. Modal shift и эрозия осторожности формулировок
Что наблюдали: в переводах систематически терялась модальность. «You may consider these metrics» → «Используйте эти метрики». «This approach often works» → «Этот подход работает». «Recommended in most cases» → «Рекомендуется». Hedges и conditionals выпадали в утверждения.
Объяснение: LLM обучены отвечать уверенно. RLHF тюнинг штрафует «слабые» формулировки и поощряет «решительные». На переводе это превращается в систематический сдвиг тональности: модель неосознанно «нормализует» осторожный английский в императивный русский. Связано с calibration issues — Tian et al. 2023, «Just Ask for Calibration».
Решение: в deep-validator-sonnet выделен отдельный
тип issue — SHIFT (modal shift), который явно
проверяется. Sentence-by-sentence alignment с цитатами с обеих
сторон делает эти сдвиги видимыми.
Урок: при переводе или суммаризации всегда проверяйте модальность. Это не «стилистическая мелочь» — это меняет смысл рекомендации с «можно подумать» на «надо делать».
4. Output token limit и обрезка длинных статей
Что наблюдали: на статье prompt-caching
(2978 строк MD) writer обрывал последние CodeGroup. Технически
модель достигала max_output_tokens и заканчивала
генерацию посередине секции — без warning'а, без явного indication.
Что нужно понимать: context window ≠ output token limit. Современные модели имеют огромный input context (200K+), но output ограничен сильнее (~32K на Opus 4.7). Длинная статья может полностью поместиться во вход, но не помещается в выход.
Решение: chained calls. Разбили задачу на три вызова: (1) скелет с placeholders, (2) развернуть CodeGroup X через Edit, (3) при необходимости добивка. Каждый вызов — отдельная задача в пределах output limit'а.
Урок: ВСЕГДА проверяйте output длинных задач на усечение. Простой эвристический сигнал — модель не закрыла последний компонент (закрывающий тег, итоговая фраза). Если это случилось — chain calls, не пытайтесь «втиснуть в один». Связанная литература: Liu et al. 2023, «Lost in the Middle» — про деградацию качества внутри длинного output'а тоже.
5. Built-in summarization в инструментах
Что наблюдали: когда брали оригинал через
WebFetch с инструкцией «верни статью целиком», модель
всё равно возвращала суммаризацию. На building-effective-agents
выпадало 5 из 7 диаграмм и половина текста.
Объяснение: WebFetch — это
«small fast model + URL» под капотом. Прежде чем дать содержимое
основной модели, он сам по себе суммаризирует длинные страницы —
это часть его design-цели (сжать, чтобы не есть context). Для
обычных задач это полезно. Для перевода — катастрофа.
Решение: где доступно — .md endpoint
через curl (raw markdown без prerender'инга).
Где недоступно — Python HTMLParser снимает текст с тегов, ничего
не суммаризируя.
Урок: понимайте семантику ваших инструментов. Многие «удобные» tools (web fetchers, file readers, code analyzers) содержат summarization step. Для воспроизведения нужны raw-каналы.
6. Glossary drift — модель тянет к «популярному» переводу
Что наблюдали: без жёсткого глоссария модель
переводила grading то как «грейдинг» (калька), то как
«оценка», то как «проверка» — даже в пределах одной статьи.
output становился «выходом», «выводом», «выходными
данными» вперемешку. evaluation и eval —
оба переводились как «оценка», теряя семантическое различие.
Объяснение: LLM не имеют persistent memory о «своих предыдущих решениях» внутри одного ответа. Каждый очередной токен — независимая sample из распределения. Если «оценка» и «проверка» примерно равновероятны, то модель будет выдавать оба, и какой выпадет — зависит от микро-контекста. Никаких внутренних рельс на «consistency» нет.
Решение: жёсткий маппинг EN→RU в системном
промпте: eval / evaluation → «оценка»,
grading → «проверка», и т.п. ~30 терминов. Validator
проверяет соблюдение глоссария grep'ом — и помечает все
нарушения.
Урок: терминологическая консистентность не возникает сама. Если в задаче важна consistent terminology — делайте explicit-глоссарий и валидируйте его соблюдение detrministic'ными проверками (grep, regex, lookup table).
7. Validator hallucinations: «нашёл» проблему которой нет
Что наблюдали: validator-агент иногда возвращал отчёт «параграф X отсутствует в переводе» — а параграф там был, но валидатор его не увидел из-за того что фетчил оригинал через WebFetch и WebFetch его пропустил при суммаризации. Или флагал «фабрикация: число 80%» — а оно было в оригинальной таблице, которую валидатор не загрузил.
Объяснение: LLM-as-judge тоже подвержены hallucinations. Они не «волшебно объективнее» — у них тот же набор failure modes, что и у других LLM, плюс специфический bias на over-flagging (легче сказать «нашёл проблему» чем «не нашёл, но может быть»). Wang et al. 2023, «Large Language Models are not Fair Evaluators» — каталог систематических ошибок LLM-судей.
Решение: правило «always-compare-to-source» в каждом промпте валидатора: каждое замечание ОБЯЗАНО сопровождаться цитатой оригинала. Без цитаты замечание не существует. Это deterministic-проверяемое требование, fixes ~70% false positives. Дополнительно — спот-чек 2-3 issues руками перед тем как запускать переводчика на правки по отчёту.
Урок: LLM-judge — не оракул. Его отчёт нужно валидировать тем же способом, которым валидируется любой LLM- output: цитаты, ссылки на источник, deterministic-проверка. Слепо применять fixes по отчёту судьи — рецепт регрессий.
Глоссарий пайплайна
| Термин | Что значит |
|---|---|
| writer | Агент, генерирующий перевод. У нас — faithful-translator на Opus. |
| surface-validator | Быстрая поверхностная проверка: inventory, glossary, spot-check. translation-validator на Opus. |
| deep-validator | Глубокая sentence-by-sentence + image + structural проверка на другой модели. deep-validator-sonnet на Sonnet. |
| same-model bias | Эффект, когда writer и validator на одной модели имеют общие blind spots. |
| триангуляция | Запуск проверки на 2+ разных моделях, сравнение расхождений. |
| faithful translation | Перевод с сохранением структуры и смысла 1:1, без упрощений и пересказов. |
| inventory diff | Сравнение количества структурных элементов (h2, details, tables) в оригинале и переводе. |
| modal shift | Смысловой сдвиг через изменение модальности: «may» → «must», «consider» → «do». |
| same-model bias | Та же модель в роли writer и validator не видит своих ошибок. |
| chained translator calls | Разбиение длинной статьи на несколько вызовов writer'а с состоянием через файл. |
| evaluator-optimizer | Workflow паттерн: один LLM генерирует, другой оценивает, в цикле. |
Что не доделано
Для прозрачности.
- Команда
/render-check— visual-сверка через headless browser. Сейчас эту функцию частично выполняет Phase A + B внутри deep-validator. Отдельная команда нужна только если захочется массовый dashboard по всем 25 статьям без semantic-check'а. - Persona-adapter агент для
publish/docs-sonya/иpublish/docs-vanya/. Эти адаптации сейчас сделаны вручную; их генерация автоматическим агентом — отдельная задача после полной валидацииpublish/docs/. - Авто-применение fix'ов по отчёту deep-validator — намеренно не делается. Subagent репортит, основной Claude правит вручную через Edit с обязательной сверкой по оригиналу. Это дисциплина против «исправлений по интуиции».
- Подсветка синтаксиса в блоках кода через Prism.js — записано в
IDEAS.md, не реализовано.
Где смотреть детали в репо
Все упомянутые промпты, журналы и cookbook'и — в репозитории проекта. Исходник этой статьи — там же.
CLAUDE.mdв корне репо — навигация по всей инфраструктуре, правила проекта..claude/agents/— текст промптов трёх subagent'ов (faithful-translator, translation-validator, deep-validator-sonnet/opus).personal/prompts/source-fetching-cookbook.md— приёмы получения оригиналов:.mdendpoints, HTMLParser snippet, обработка hidelines, картинок и SPA-страниц.personal/prompts/mintlify-mappings.md— карта компонентов Mintlify в наш HTML.personal/retranslate-log.md— журнал всех 25 переводов с verdict'ами и применёнными правками.personal/deep-validation-log.md+-sonnet.md+-opus.md— план и журналы глубокой валидации.
История версий статьи
| Версия | Дата | Что изменилось |
|---|---|---|
| 1.0 | 2026-04-26 | Первая версия. Описаны 4 версии пайплайна (v1-v4), 7 case study'ев, теория evaluator-optimizer и same-model bias. |