Contextual Retrieval
Чтобы AI-модель была полезна в конкретных контекстах, ей часто нужен доступ к фоновым знаниям. Например, чат-боты клиентской поддержки должны знать о конкретном бизнесе, для которого они используются, а боты для юридического анализа — об огромном множестве прошлых дел.
Разработчики обычно расширяют знания AI-модели с помощью Retrieval-Augmented Generation (RAG). RAG — это метод, который извлекает релевантную информацию из базы знаний и добавляет её к промпту пользователя, существенно улучшая ответ модели. Проблема в том, что традиционные RAG-решения удаляют контекст при кодировании информации, из-за чего система часто не находит нужную информацию в базе знаний.
В этом посте мы описываем метод, который существенно улучшает шаг retrieval в RAG. Метод называется «Contextual Retrieval» и использует две суб-техники: Contextual Embeddings и Contextual BM25. Этот метод может уменьшить количество неудачных retrieval на 49%, а в сочетании с reranking — на 67%. Это значительные улучшения в точности retrieval, которые напрямую приводят к лучшим результатам в downstream-задачах.
Вы можете легко развернуть собственное решение Contextual Retrieval с Claude через наш cookbook.
Замечание о том, чтобы просто использовать более длинный промпт
Иногда самое простое решение — лучшее. Если ваша база знаний меньше 200 000 tokens (около 500 страниц материала), вы можете просто включить всю базу знаний в промпт, который вы даёте модели, без необходимости в RAG или подобных методах.
Несколько недель назад мы выпустили prompt caching для Claude, что делает этот подход существенно быстрее и экономичнее. Разработчики теперь могут кешировать часто используемые промпты между вызовами API, уменьшая задержку более чем в 2 раза и стоимость до 90% (как это работает — см. наш cookbook по prompt caching).
Однако по мере роста базы знаний вам понадобится более масштабируемое решение. Тут и приходит Contextual Retrieval.
Введение в RAG: масштабирование на большие базы знаний
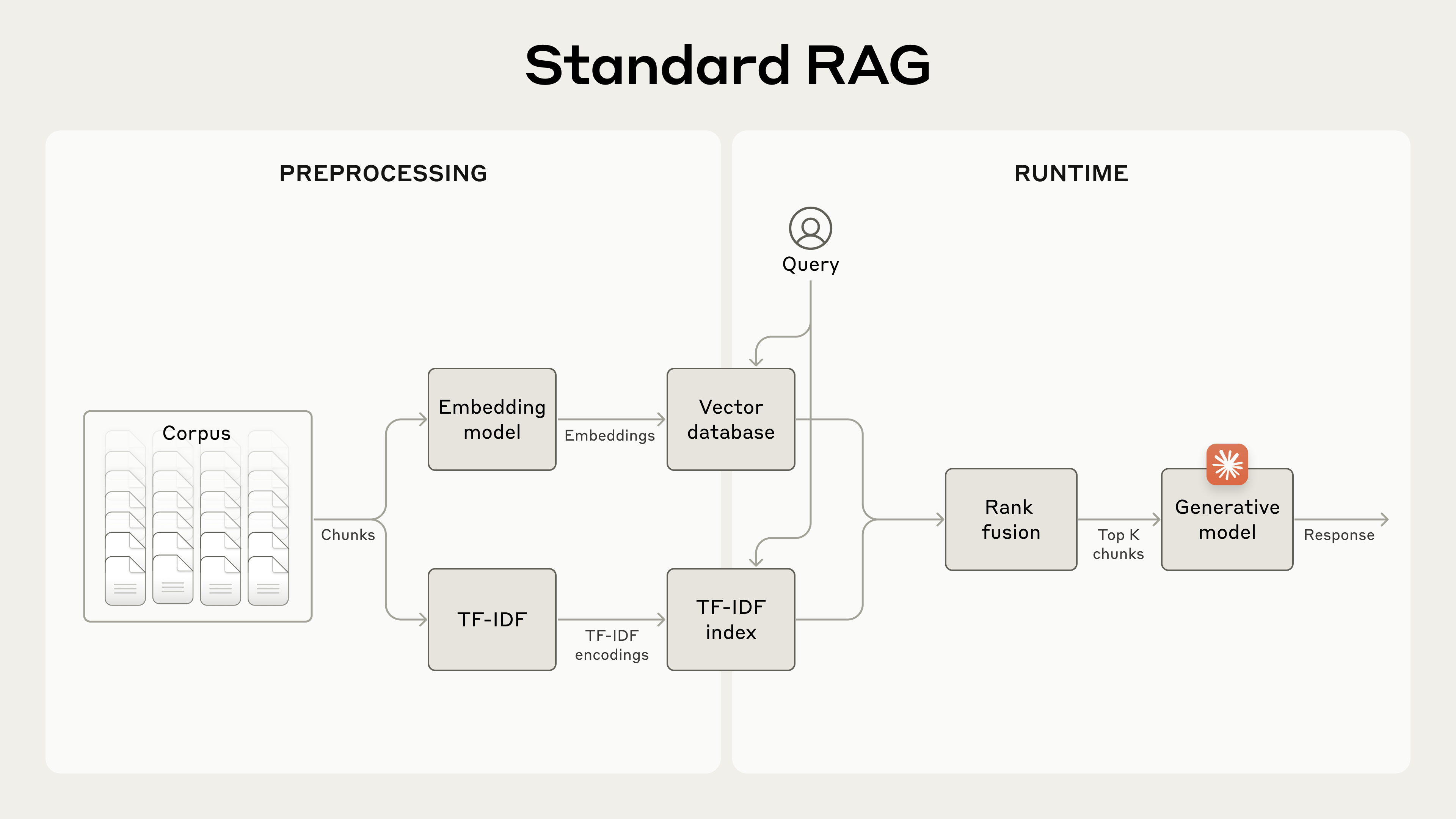
Для больших баз знаний, которые не помещаются в context window, RAG — типичное решение. RAG работает, предобрабатывая базу знаний по следующим шагам:
- Разбить базу знаний («корпус» документов) на меньшие chunks текста, обычно не более нескольких сотен tokens;
- Использовать embedding-модель, чтобы преобразовать эти chunks в векторные embeddings, кодирующие смысл;
- Сохранить эти embeddings в векторной базе данных, которая позволяет искать по семантическому сходству.
Во время выполнения, когда пользователь вводит запрос модели, векторная база данных используется, чтобы найти наиболее релевантные chunks по семантическому сходству с запросом. Затем самые релевантные chunks добавляются к промпту, отправляемому генеративной модели.
Хотя embedding-модели отлично улавливают семантические связи, они могут пропускать критически важные точные совпадения. К счастью, есть более старая техника, которая может помочь в таких ситуациях. BM25 (Best Matching 25) — это ранжирующая функция, использующая лексическое сопоставление, чтобы находить точные совпадения слов или фраз. Особенно эффективна для запросов, содержащих уникальные идентификаторы или технические термины.
BM25 работает, опираясь на концепцию TF-IDF (Term Frequency-Inverse Document Frequency). TF-IDF измеряет, насколько слово важно для документа в коллекции. BM25 уточняет это, учитывая длину документа и применяя функцию насыщения к частоте термина, что помогает не дать частым словам доминировать в результатах.
Вот как BM25 может преуспеть там, где семантические embeddings не справляются: предположим, пользователь запрашивает «Error code TS-999» в базе технической поддержки. Embedding-модель может найти контент о кодах ошибок в целом, но пропустить точное совпадение «TS-999». BM25 ищет именно эту строку текста, чтобы найти нужную документацию.
RAG-решения могут более точно извлекать наиболее подходящие chunks, комбинируя embeddings и BM25 по следующим шагам:
- Разбить базу знаний («корпус» документов) на меньшие chunks текста, обычно не более нескольких сотен tokens;
- Создать TF-IDF-кодирования и семантические embeddings для этих chunks;
- Использовать BM25, чтобы найти топ-chunks на основе точных совпадений;
- Использовать embeddings, чтобы найти топ-chunks на основе семантического сходства;
- Объединить и дедуплицировать результаты из (3) и (4) с помощью техник rank fusion;
- Добавить top-K chunks к промпту, чтобы сгенерировать ответ.
Используя и BM25, и embedding-модели, традиционные RAG-системы могут давать более полные и точные результаты, балансируя между точным сопоставлением терминов и более широким семантическим пониманием.
Этот подход позволяет экономично масштабироваться на огромные базы знаний — намного больше того, что помещается в один промпт. Но у этих традиционных RAG-систем есть существенное ограничение: они часто разрушают контекст.
Загвоздка с контекстом в традиционном RAG
В традиционном RAG документы обычно разбиваются на меньшие chunks для эффективного retrieval. Хотя такой подход хорошо работает для многих приложений, он может приводить к проблемам, когда отдельным chunks не хватает контекста.
Например, представьте, что у вас есть коллекция финансовой информации (скажем, отчёты SEC США), встроенная в вашу базу знаний, и вы получили следующий вопрос: «Какой был рост выручки у ACME Corp в Q2 2023?»
Релевантный chunk может содержать текст: «Выручка компании выросла на 3% по сравнению с предыдущим кварталом.» Однако этот chunk сам по себе не уточняет, о какой именно компании речь и какой период имеется в виду, что затрудняет извлечение нужной информации или её эффективное использование.
Знакомство с Contextual Retrieval
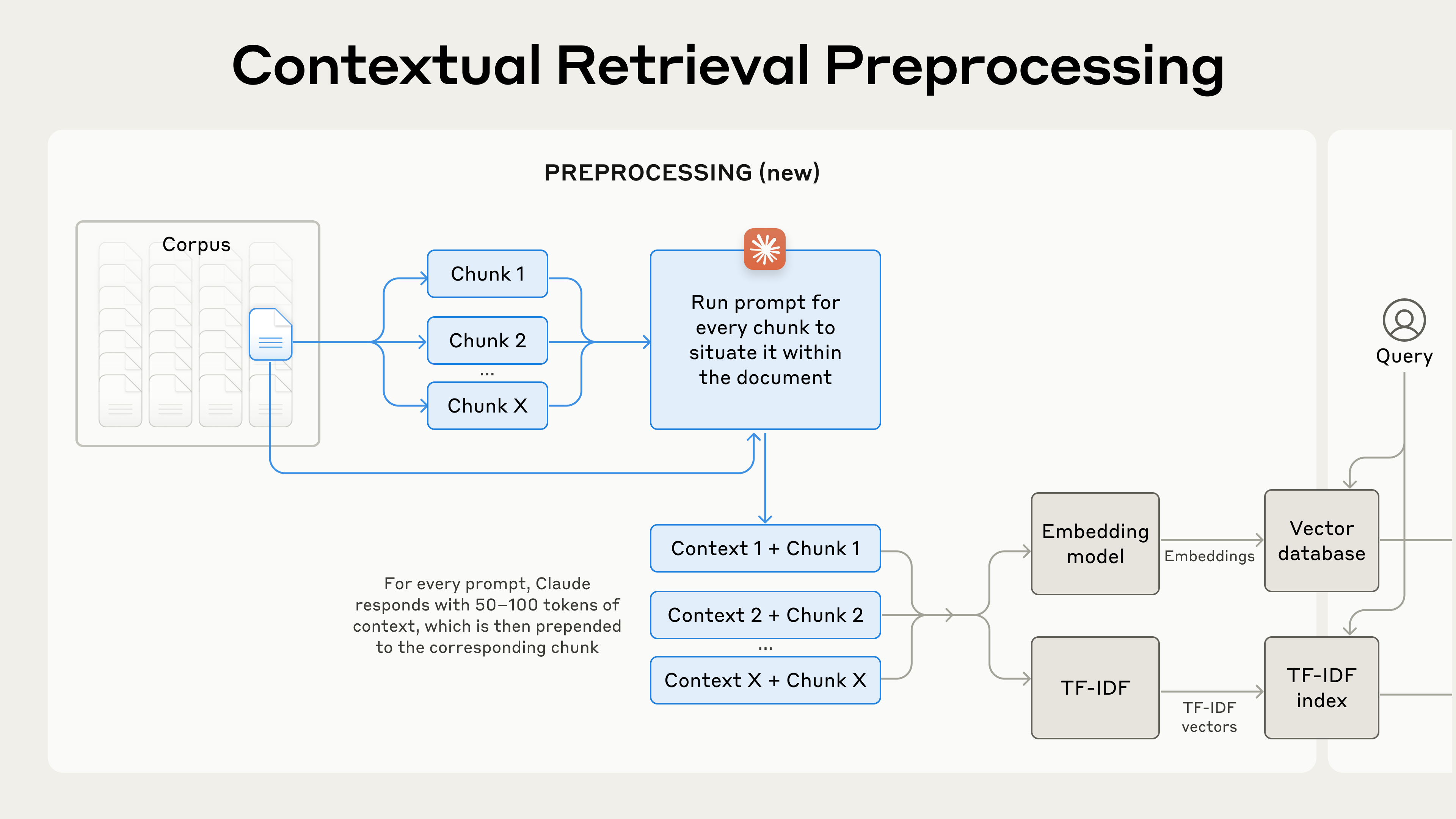
Contextual Retrieval решает эту проблему, добавляя к каждому chunk специфичный для него поясняющий контекст перед embedding («Contextual Embeddings») и созданием BM25-индекса («Contextual BM25»).
Вернёмся к нашему примеру с отчётами SEC. Вот как chunk может быть преобразован:
original_chunk = "The company's revenue grew by 3% over the previous quarter."
contextualized_chunk = "This chunk is from an SEC filing on ACME corp's performance in Q2 2023; the previous quarter's revenue was $314 million. The company's revenue grew by 3% over the previous quarter."
Стоит отметить, что в прошлом предлагались и другие подходы к использованию контекста для улучшения retrieval. Среди них: добавление общих сводок документа к chunks (мы экспериментировали и увидели очень ограниченные улучшения), hypothetical document embedding и summary-based indexing (мы оценили и увидели низкое качество). Эти методы отличаются от того, что предлагается в этом посте.
Реализация Contextual Retrieval
Конечно, было бы слишком трудозатратно вручную аннотировать тысячи или даже миллионы chunks в базе знаний. Чтобы реализовать Contextual Retrieval, мы обращаемся к Claude. Мы написали промпт, который инструктирует модель давать краткий, специфичный для chunk контекст, объясняющий chunk через контекст всего документа. Мы использовали следующий промпт для Claude 3 Haiku, чтобы генерировать контекст для каждого chunk:
<document>
{{WHOLE_DOCUMENT}}
</document>
Here is the chunk we want to situate within the whole document
<chunk>
{{CHUNK_CONTENT}}
</chunk>
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk. Answer only with the succinct context and nothing else.
Получившийся контекстный текст, обычно 50–100 tokens, добавляется в начало chunk перед его embedding и перед созданием BM25-индекса.
Вот как выглядит этот процесс предобработки на практике:
Если вам интересно использовать Contextual Retrieval, вы можете начать с нашего cookbook.
Использование Prompt Caching, чтобы уменьшить стоимость Contextual Retrieval
Contextual Retrieval уникально возможен по низкой цене с Claude благодаря специальной функции prompt caching, которую мы упоминали выше. С prompt caching вам не нужно передавать справочный документ для каждого chunk. Вы просто загружаете документ в кеш один раз и затем ссылаетесь на ранее закешированный контент. При условии chunks по 800 tokens, документов по 8k tokens, инструкций контекста по 50 tokens и контекста по 100 tokens на chunk, единоразовая стоимость генерации контекстуализированных chunks составляет $1.02 на миллион tokens документа.
Методология
Мы экспериментировали в различных предметных областях знаний (codebases, художественная литература, статьи ArXiv, научные статьи), embedding-моделях, стратегиях retrieval и метриках оценки. Мы включили несколько примеров вопросов и ответов, которые мы использовали для каждой области, в Приложение II.
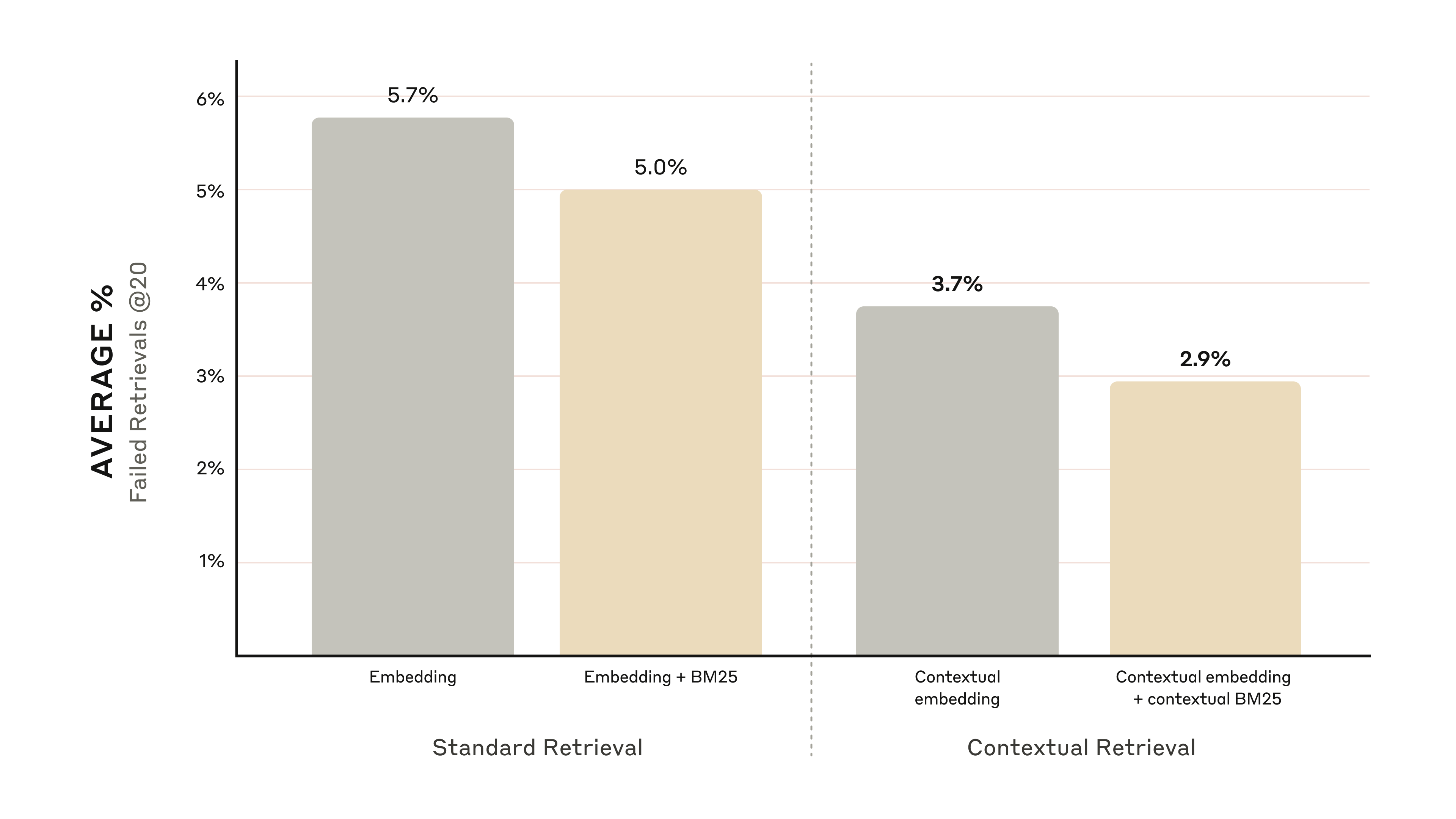
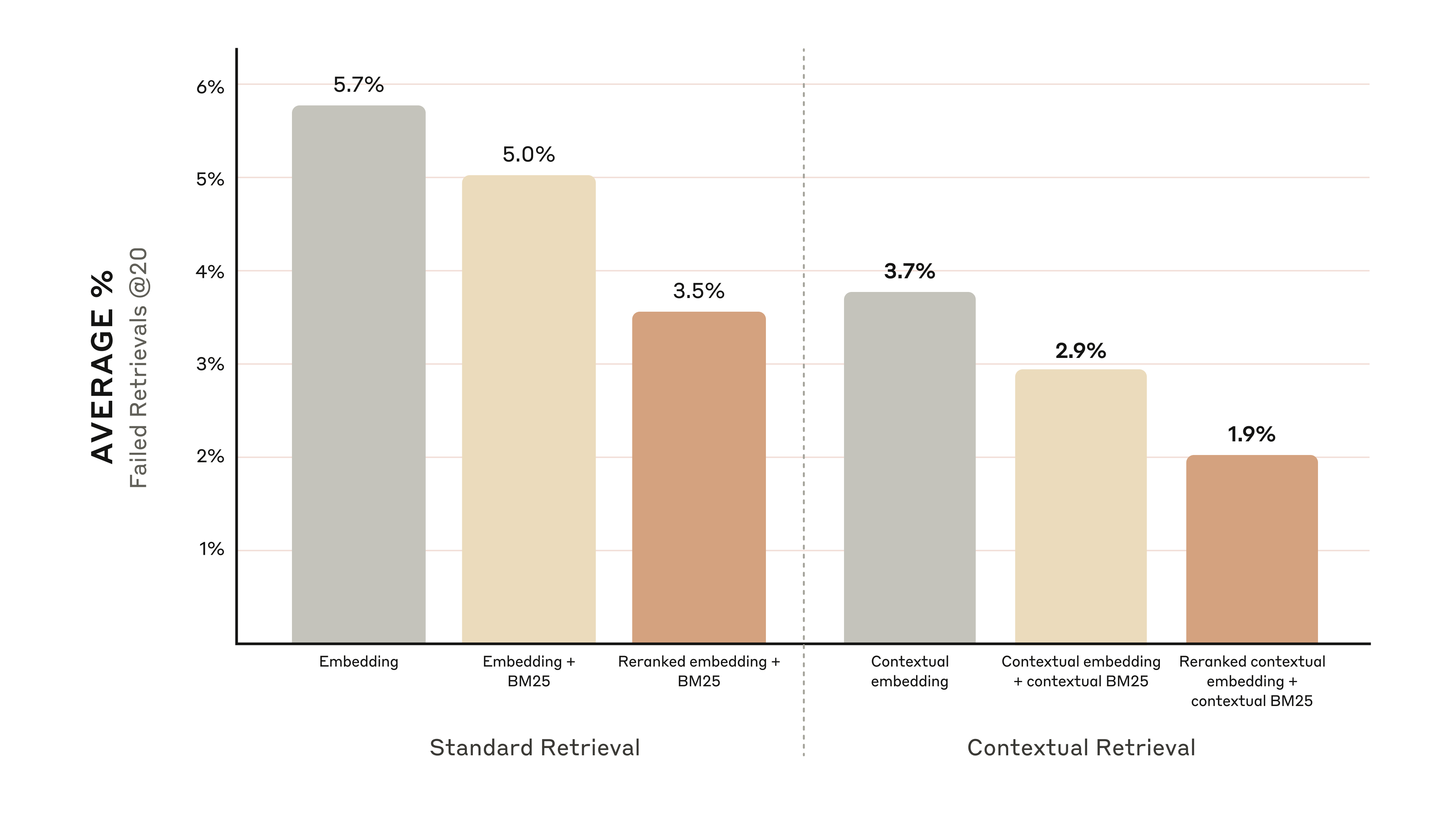
Графики ниже показывают средние результаты по всем предметным областям с лучшей конфигурацией embedding (Gemini Text 004) и retrieval топ-20-chunks. Мы используем 1 минус recall@20 как нашу метрику оценки, которая измеряет процент релевантных документов, не извлечённых в топ-20 chunks. Полные результаты — в приложении; контекстуализация улучшает результаты в каждой комбинации embedding-source, которую мы оценили.
Улучшения результатов
Наши эксперименты показали, что:
- Contextual Embeddings уменьшил частоту неудачных retrieval топ-20-chunks на 35% (5.7% → 3.7%).
- Сочетание Contextual Embeddings и Contextual BM25 уменьшило частоту неудачных retrieval топ-20-chunks на 49% (5.7% → 2.9%).
Соображения по реализации
При реализации Contextual Retrieval стоит учесть несколько моментов:
- Границы chunks: подумайте, как вы разбиваете документы на chunks. Выбор размера chunk, границы chunk и наложения chunks может влиять на качество retrieval1.
- Embedding-модель: хотя Contextual Retrieval улучшает результаты во всех протестированных нами embedding-моделях, некоторые могут выигрывать больше, чем другие. Мы обнаружили, что embeddings Gemini и Voyage особенно эффективны.
- Кастомные промпты для контекстуализатора: хотя общий промпт, который мы предоставили, работает хорошо, вы можете достичь ещё лучших результатов с промптами, заточенными под вашу конкретную область или сценарий использования (например, включив глоссарий ключевых терминов, которые могут быть определены только в других документах базы знаний).
- Количество chunks: добавление большего числа chunks в context window увеличивает шансы, что вы включите релевантную информацию. Однако больше информации может отвлекать модели, поэтому здесь есть предел. Мы пробовали передавать 5, 10 и 20 chunks и обнаружили, что 20 — самый результативный из этих вариантов (см. сравнения в приложении), но стоит поэкспериментировать на вашем сценарии использования.
Всегда запускайте оценки: генерацию ответа можно улучшить, передавая контекстуализированный chunk и различая, что является контекстом, а что — самим chunk.
Дальнейшее улучшение результатов с Reranking
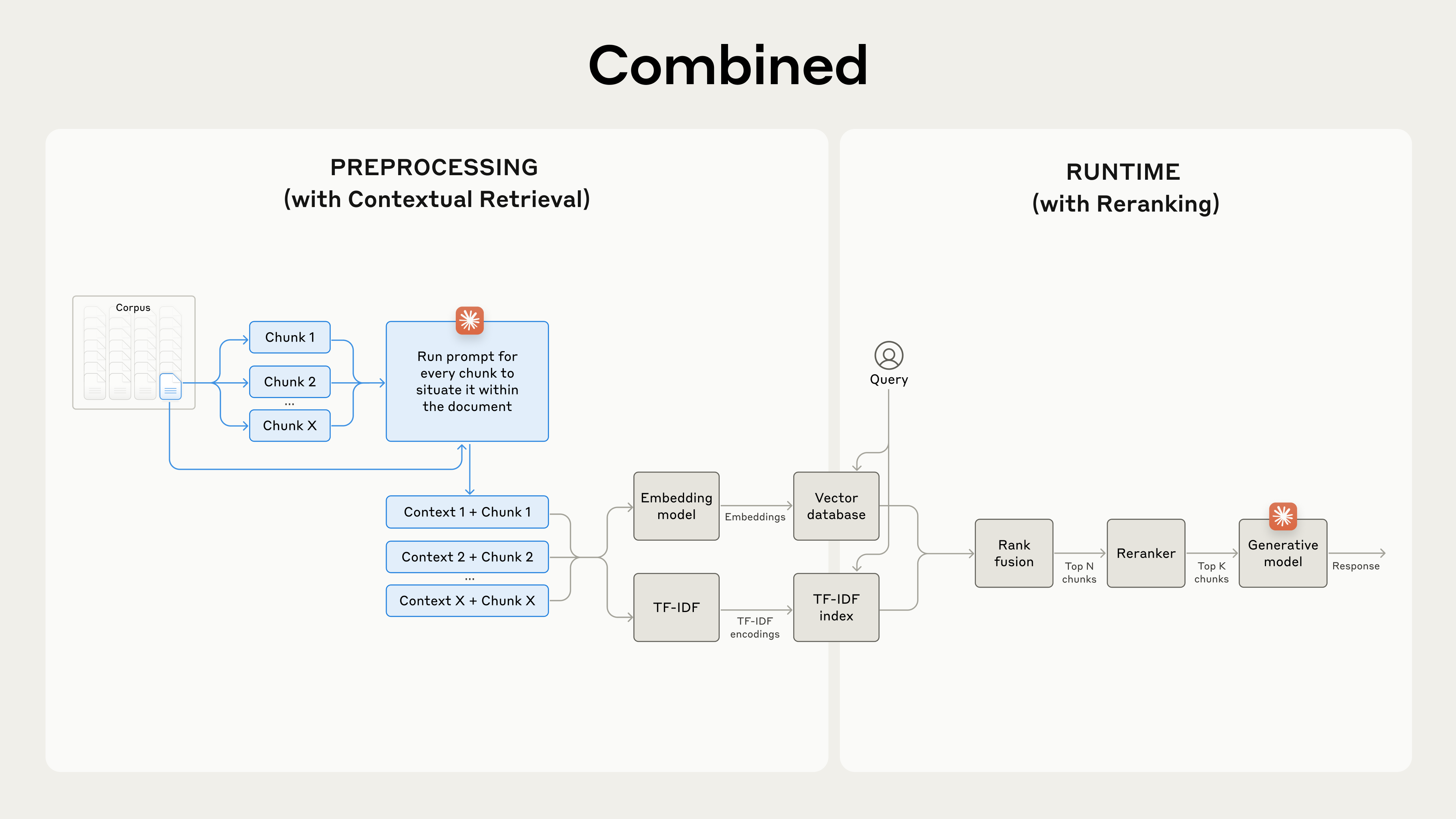
На последнем шаге мы можем сочетать Contextual Retrieval с ещё одной техникой, чтобы получить ещё больше улучшений. В традиционном RAG AI-система ищет в базе знаний потенциально релевантные chunks информации. С большими базами знаний это первичное retrieval часто возвращает много chunks — иногда сотни — разной релевантности и важности.
Reranking — широко используемая техника фильтрации, чтобы убедиться, что только самые релевантные chunks передаются модели. Reranking даёт лучшие ответы и снижает стоимость и задержку, потому что модель обрабатывает меньше информации. Ключевые шаги:
- Выполнить первичное retrieval, чтобы получить топ потенциально релевантных chunks (мы использовали топ-150);
- Прогнать топ-N chunks вместе с запросом пользователя через reranking-модель;
- Используя reranking-модель, дать каждому chunk балл на основе его релевантности и важности для промпта, затем выбрать топ-K chunks (мы использовали топ-20);
- Передать топ-K chunks в модель как контекст, чтобы сгенерировать финальный результат.
Улучшения результатов
На рынке есть несколько reranking-моделей. Мы провели тесты с Cohere reranker. Voyage также предлагает reranker, но у нас не было времени его протестировать. Наши эксперименты показали, что в различных областях добавление шага reranking дополнительно оптимизирует retrieval.
В частности, мы обнаружили, что Reranked Contextual Embedding и Contextual BM25 уменьшили частоту неудачных retrieval топ-20-chunks на 67% (5.7% → 1.9%).
Соображения по стоимости и задержке
Одно важное соображение с reranking — влияние на задержку и стоимость, особенно при reranking большого числа chunks. Поскольку reranking добавляет дополнительный шаг во время выполнения, он неизбежно добавляет небольшое количество задержки, даже если reranker оценивает все chunks параллельно. Существует неизбежный компромисс между reranking большего числа chunks для лучших результатов и reranking меньшего для меньшей задержки и стоимости. Мы рекомендуем экспериментировать с разными настройками на вашем конкретном сценарии использования, чтобы найти правильный баланс.
Заключение
Мы провели большое количество тестов, сравнивая разные сочетания всех описанных выше техник (embedding-модель, использование BM25, использование contextual retrieval, использование reranker и общее число извлечённых top-K результатов) на разнообразных типах датасетов. Вот сводка того, что мы обнаружили:
- Embeddings+BM25 лучше, чем embeddings сами по себе;
- Voyage и Gemini имеют лучшие embeddings из тех, что мы тестировали;
- Передача топ-20 chunks модели эффективнее, чем только топ-10 или топ-5;
- Добавление контекста к chunks сильно улучшает точность retrieval;
- Reranking лучше, чем без reranking;
- Все эти преимущества складываются: чтобы максимизировать улучшения, мы можем сочетать contextual embeddings (от Voyage или Gemini) с contextual BM25 плюс шаг reranking, а также добавлять 20 chunks в промпт.
Мы призываем всех разработчиков, работающих с базами знаний, использовать наш cookbook, чтобы экспериментировать с этими подходами и открывать новые уровни результатов.
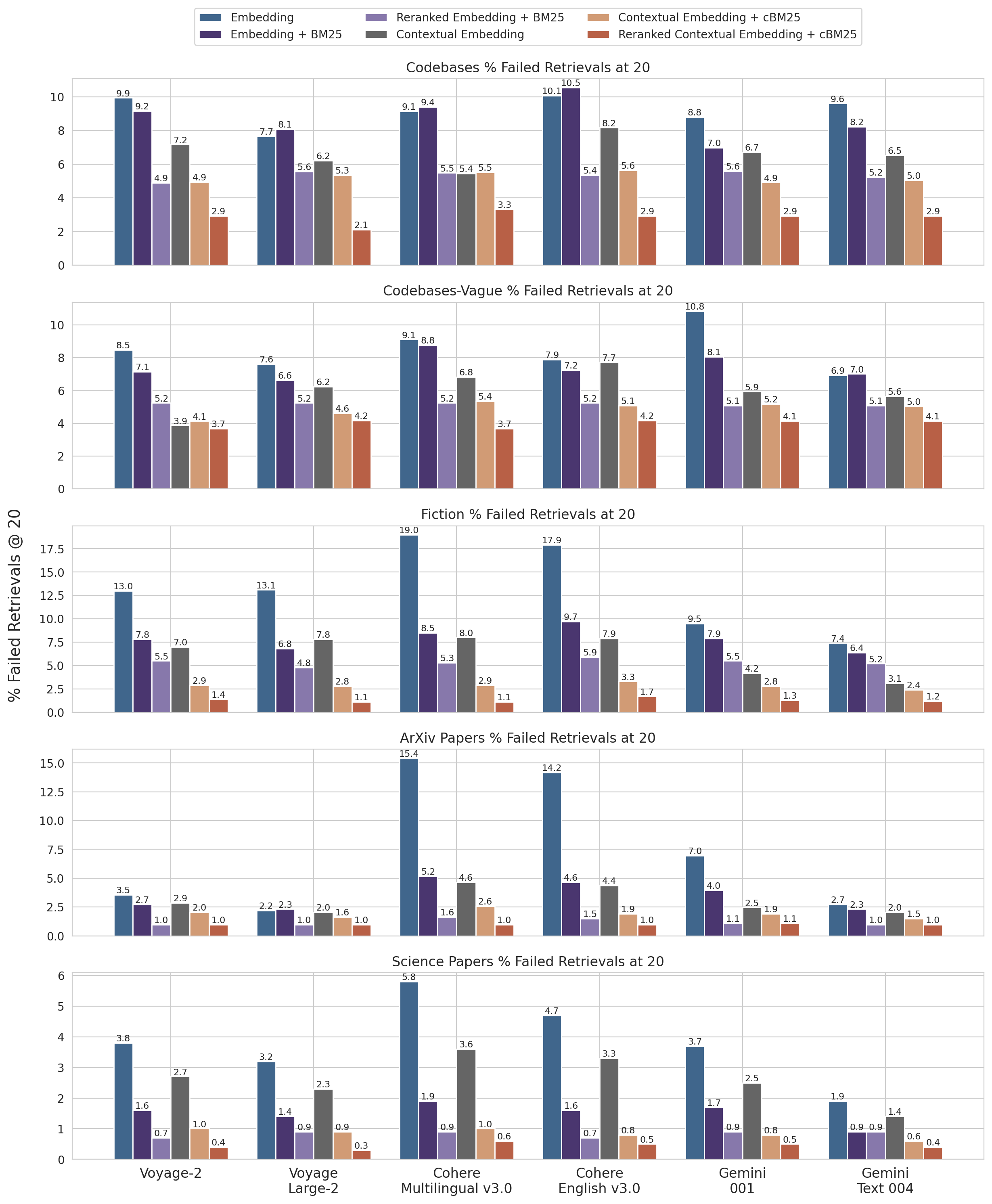
Приложение I
Ниже — разбивка результатов по датасетам, провайдерам embeddings, использованию BM25 в дополнение к embeddings, использованию contextual retrieval и использованию reranking для Retrievals @ 20.
См. Приложение II для разбивок по Retrievals @ 10 и @ 5, а также примеров вопросов и ответов для каждого датасета.
Благодарности
Исследование и текст — Daniel Ford. Спасибо Orowa Sikder, Gautam Mittal и Kenneth Lien за критическую обратную связь, Samuel Flamini за реализацию cookbooks, Lauren Polansky за координацию проекта и Alex Albert, Susan Payne, Stuart Ritchie и Brad Abrams за формирование этого блог-поста.