Как строить эффективные агенты
За последний год мы работали с десятками команд, которые строят агентов на больших языковых моделях (LLM) в самых разных отраслях. Раз за разом самые успешные реализации использовали простые, композируемые паттерны, а не сложные фреймворки или специализированные библиотеки.
В этом посте мы делимся тем, что узнали за время работы с нашими клиентами и при создании собственных агентов, и даём разработчикам практические советы по построению эффективных агентов.
Что такое агенты?
«Агента» можно определить по-разному. Некоторые клиенты определяют агентов как полностью автономные системы, которые работают независимо в течение длительного времени, используя различные tools для решения сложных задач. Другие используют этот термин, чтобы описать более предписывающие реализации, следующие заранее заданным workflow. В Anthropic мы относим все эти варианты к агентным системам, но проводим важное архитектурное различие между workflow и агентами:
- Workflow — это системы, в которых LLM и tools оркестрируются через заранее заданные code paths.
- Агенты, напротив, — это системы, в которых LLM динамически направляют собственные процессы и использование tools, сохраняя контроль над тем, как они решают задачи.
Ниже мы подробно разберём оба типа агентных систем. В Приложении 1 («Агенты на практике») мы описываем две области, в которых клиенты нашли особую ценность в использовании таких систем.
Когда (и когда не стоит) использовать агентов
При построении приложений с LLM мы рекомендуем находить максимально простое решение и наращивать сложность только при необходимости. Это может означать вообще не строить агентные системы. Агентные системы часто меняют задержку и стоимость на лучшее качество выполнения задачи, и стоит подумать, когда такой компромисс имеет смысл.
Когда дополнительная сложность оправдана, workflow дают предсказуемость и консистентность для чётко определённых задач, тогда как агенты — лучший вариант, когда нужна гибкость и принятие решений на основе модели в масштабе. Однако для многих приложений достаточно оптимизировать одиночные LLM-вызовы с retrieval и in-context примерами.
Когда и как использовать фреймворки
Существует много фреймворков, упрощающих реализацию агентных систем, среди них:
- Claude Agent SDK;
- Strands Agents SDK от AWS;
- Rivet — drag and drop GUI-конструктор LLM workflow;
- Vellum — ещё один GUI-инструмент для построения и тестирования сложных workflow.
Эти фреймворки облегчают старт, упрощая стандартные низкоуровневые задачи: вызов LLM, определение и парсинг tools, склейку вызовов друг с другом. Однако они часто создают дополнительные слои абстракции, которые могут скрывать исходные prompts и ответы и затруднять отладку. Они же могут провоцировать добавлять сложность там, где хватило бы более простой настройки.
Мы советуем разработчикам начинать с прямого использования LLM API: многие паттерны можно реализовать в несколько строк кода. Если вы всё-таки используете фреймворк, убедитесь, что понимаете код под капотом. Неверные предположения о том, что находится внутри, — частый источник ошибок наших клиентов.
Образцы реализаций можно посмотреть в нашем cookbook.
Строительные блоки, workflow и агенты
В этом разделе мы разберём общие паттерны для агентных систем, которые видели в production. Начнём с фундаментального строительного блока — расширенной LLM — и постепенно будем наращивать сложность: от простых композиционных workflow до автономных агентов.
Строительный блок: расширенная LLM
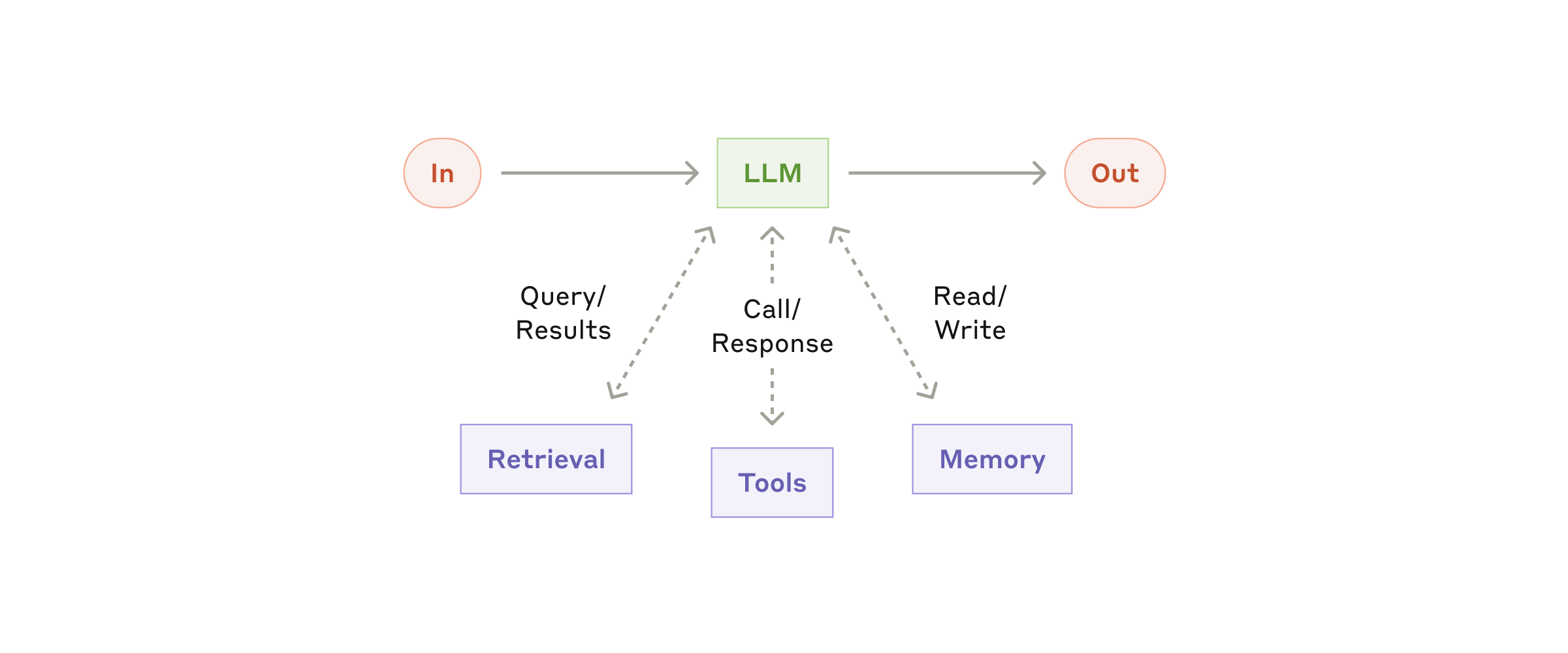
Базовый строительный блок агентных систем — это LLM, расширенная такими дополнениями, как retrieval, tools и память. Наши текущие модели умеют активно использовать эти возможности — формировать собственные поисковые запросы, выбирать подходящие tools и решать, какую информацию сохранять.
Мы рекомендуем сосредоточиться на двух ключевых аспектах реализации: подгонке этих возможностей под ваш конкретный сценарий использования и обеспечении удобного, хорошо документированного интерфейса для вашей LLM. Реализовать эти расширения можно по-разному, и один из подходов — через наш недавно выпущенный Model Context Protocol, который позволяет разработчикам интегрироваться с растущей экосистемой сторонних tools при простой реализации клиента.
В оставшейся части поста мы будем считать, что у каждого LLM-вызова есть доступ к этим расширенным возможностям.
Workflow: prompt chaining
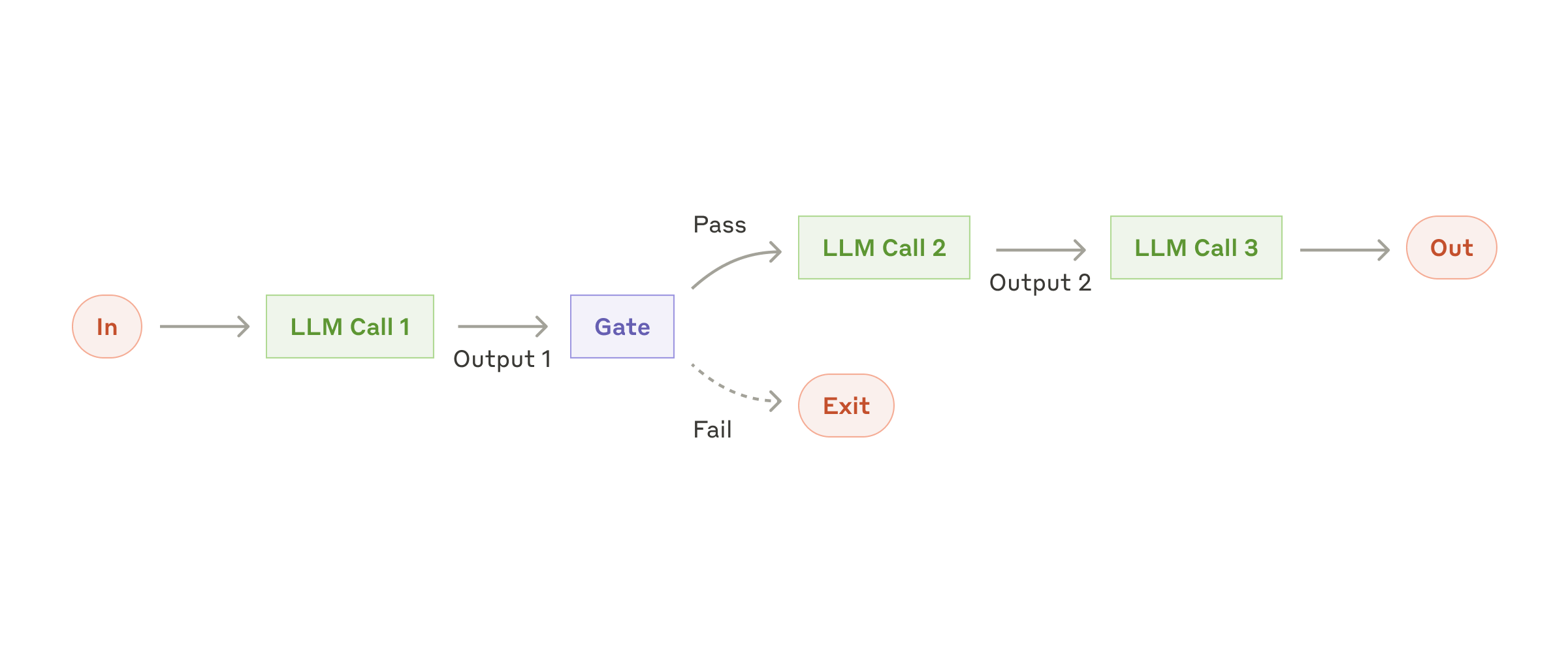
Prompt chaining раскладывает задачу на последовательность шагов, где каждый LLM-вызов обрабатывает выходные данные предыдущего. На любом промежуточном шаге можно добавить программные проверки (см. «gate» на диаграмме ниже), чтобы убедиться, что процесс по-прежнему идёт по плану.
Когда использовать этот workflow: этот workflow идеально подходит для ситуаций, когда задача легко и чисто раскладывается на фиксированные подзадачи. Главная цель — обменять задержку на более высокую точность, делая каждый LLM-вызов более простой задачей.
Примеры, где prompt chaining полезен:
- Сгенерировать маркетинговый текст, а затем перевести его на другой язык.
- Написать план документа, проверить, что план соответствует определённым критериям, и затем написать документ по плану.
Workflow: routing
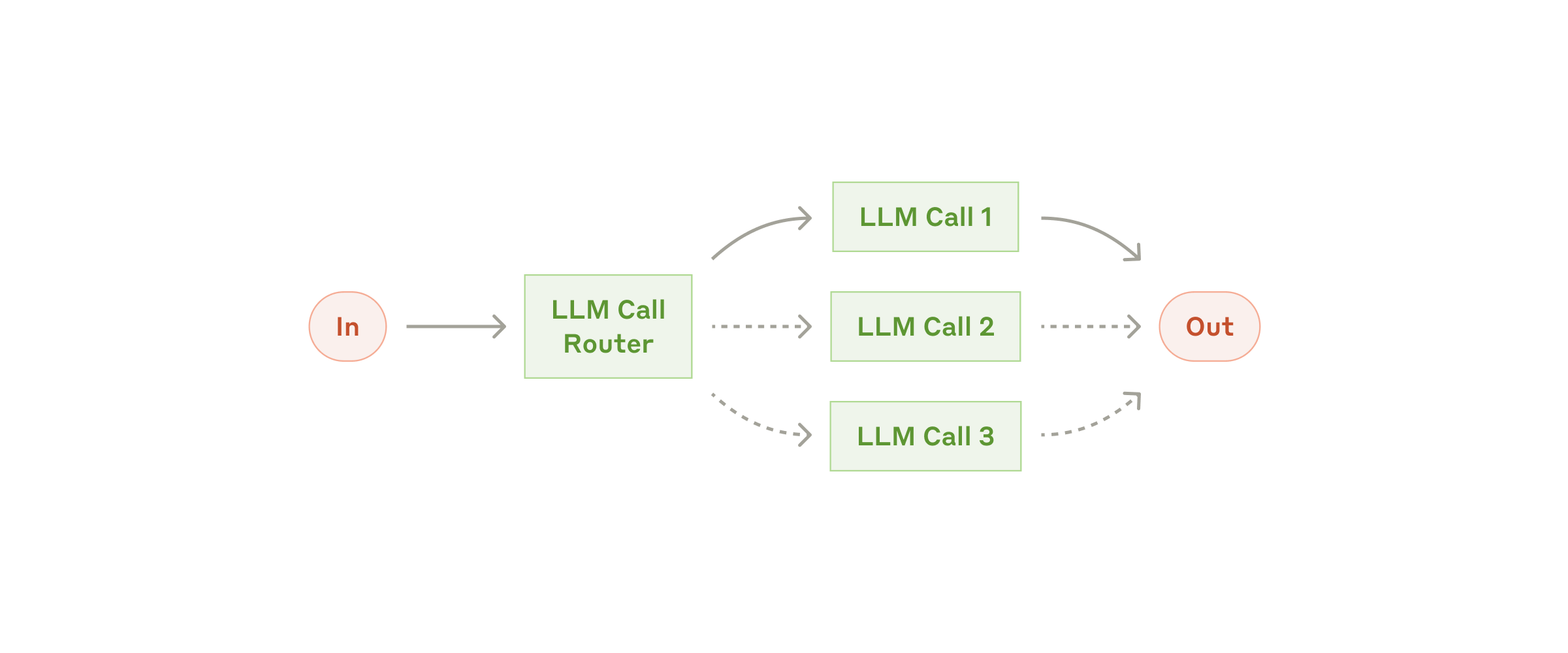
Routing классифицирует входные данные и направляет их в специализированную последующую задачу. Этот workflow позволяет разделять ответственность и строить более специализированные prompts. Без него оптимизация под один вид входных данных может ухудшить работу на других.
Когда использовать этот workflow: routing хорошо работает для сложных задач, в которых есть отдельные категории, лучше обрабатываемые по отдельности, и в которых классификацию можно делать достаточно точно — будь то LLM или более традиционная классификационная модель/алгоритм.
Примеры, где routing полезен:
- Направление разных типов запросов в клиентскую поддержку (общие вопросы, запросы на возврат, техподдержка) в разные downstream-процессы, prompts и tools.
- Маршрутизация лёгких/частых вопросов в меньшие, более экономичные модели вроде Claude Haiku 4.5, а сложных/нетипичных — в более мощные модели вроде Claude Sonnet 4.5, чтобы оптимизировать под лучший результат.
Workflow: parallelization
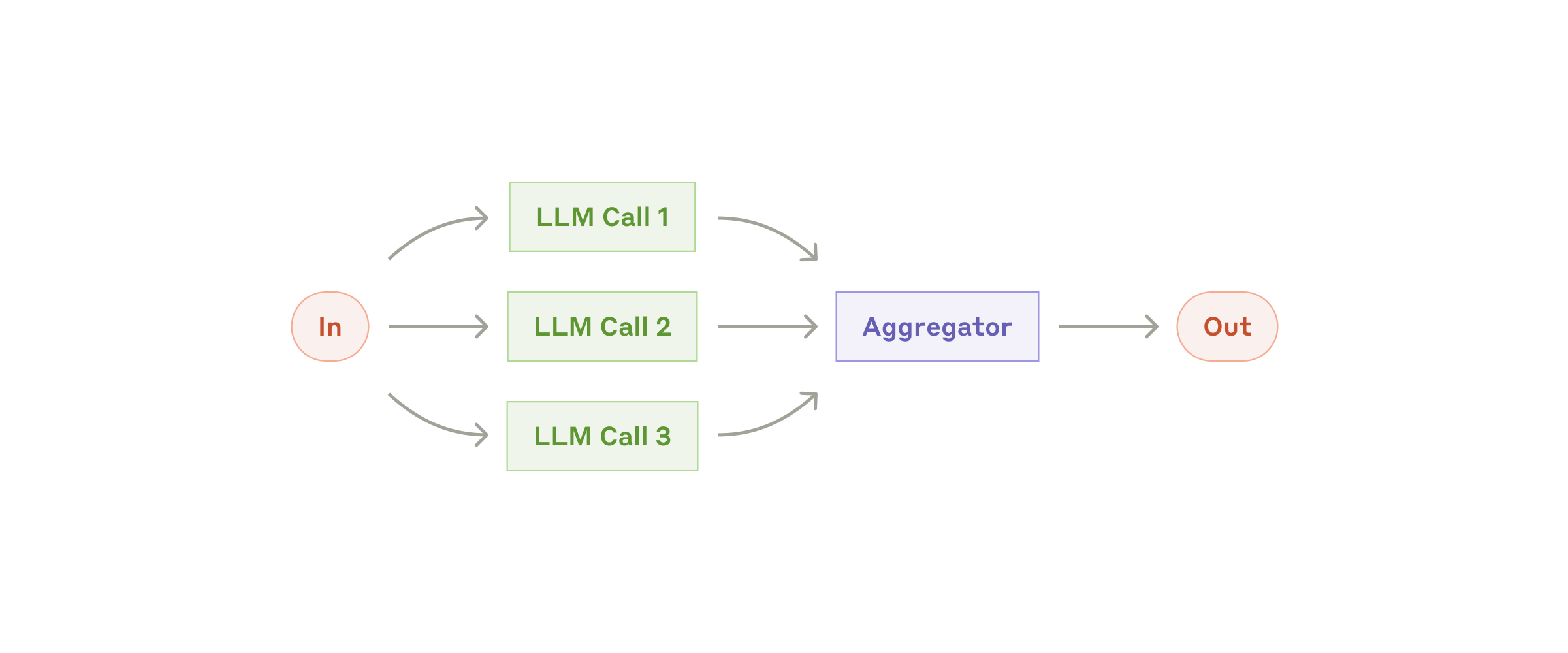
LLM иногда могут работать над задачей одновременно, а их выходные данные программно агрегироваться. Этот workflow, parallelization, проявляется в двух ключевых вариантах:
- Sectioning: разбиение задачи на независимые подзадачи, выполняемые параллельно.
- Voting: выполнение одной и той же задачи несколько раз, чтобы получить разнообразные выходные данные.
Когда использовать этот workflow: parallelization эффективна, когда разделённые подзадачи можно распараллелить ради скорости, или когда нужно несколько перспектив или попыток для более уверенных результатов. Для сложных задач с множеством соображений LLM в целом работают лучше, когда каждое соображение обрабатывается отдельным LLM-вызовом, что позволяет сосредоточить внимание на конкретном аспекте.
Примеры, где parallelization полезна:
- Sectioning:
- Реализация guardrails, когда один экземпляр модели обрабатывает запросы пользователя, а другой проверяет их на неприемлемый контент или запросы. Это, как правило, работает лучше, чем поручать одному и тому же LLM-вызову и guardrails, и основной ответ.
- Автоматизация оценок для оценивания работы LLM, где каждый LLM-вызов оценивает отдельный аспект работы модели на заданном prompt.
- Voting:
- Просмотр участка кода на уязвимости, когда несколько разных prompts проверяют код и помечают его, если находят проблему.
- Оценка того, является ли заданный фрагмент контента неприемлемым: несколько prompts оценивают разные аспекты или требуют разных порогов голосования, чтобы балансировать ложноположительные и ложноотрицательные срабатывания.
Workflow: orchestrator-workers
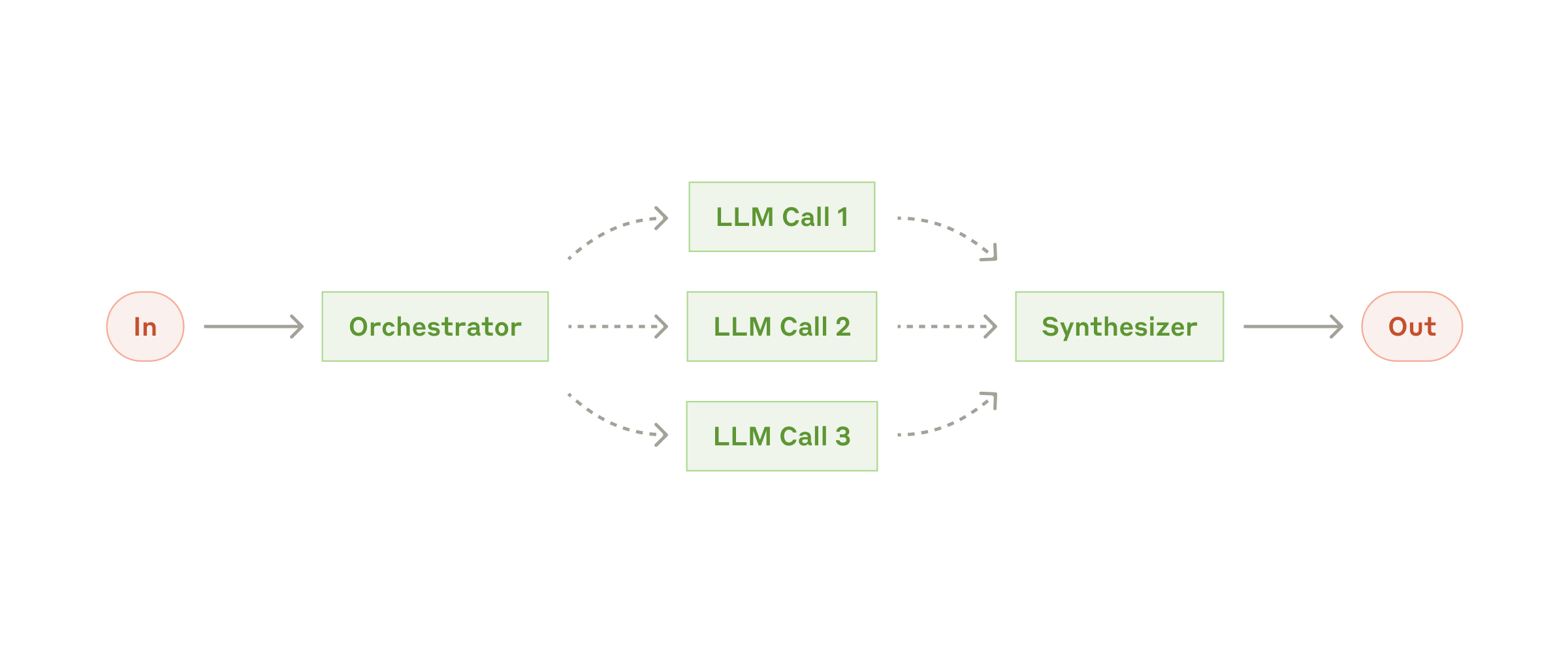
В workflow orchestrator-workers центральная LLM динамически разбивает задачи, делегирует их LLM-исполнителям и синтезирует их результаты.
Когда использовать этот workflow: этот workflow хорошо подходит для сложных задач, в которых нельзя предсказать нужные подзадачи (в коде, например, число файлов, которые нужно изменить, и характер изменения в каждом файле, скорее всего, зависят от задачи). Хотя топологически он похож на parallelization, ключевое отличие — в гибкости: подзадачи не предопределены, а определяются оркестратором на основе конкретного входа.
Пример, где orchestrator-workers полезен:
- Продукты для написания кода, которые каждый раз делают сложные изменения в нескольких файлах.
- Поисковые задачи, требующие сбора и анализа информации из нескольких источников на предмет возможной релевантной информации.
Workflow: evaluator-optimizer
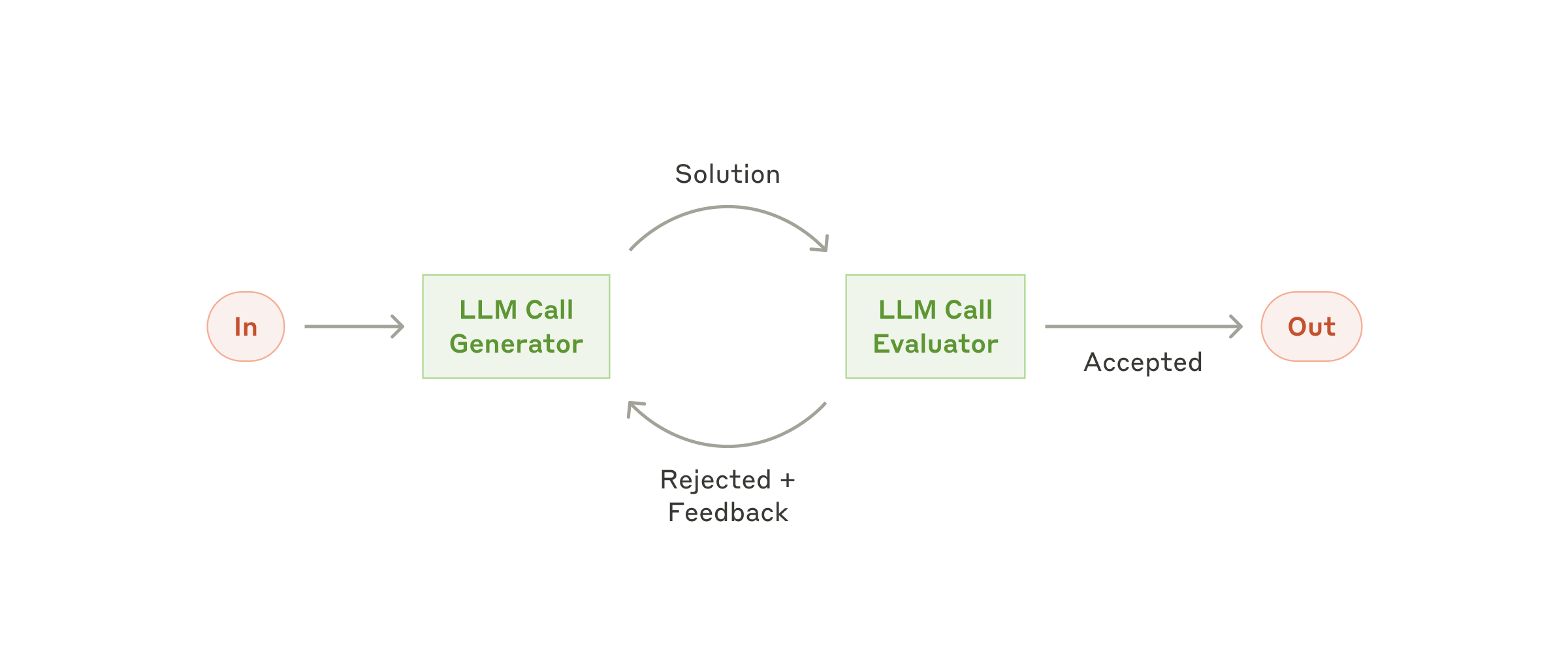
В workflow evaluator-optimizer один LLM-вызов генерирует ответ, а другой даёт оценку и обратную связь — в цикле.
Когда использовать этот workflow: этот workflow особенно эффективен, когда у нас есть чёткие критерии оценивания и когда итеративное улучшение даёт измеримую ценность. Два признака хорошего соответствия: во-первых, ответы LLM наглядно улучшаются, когда человек формулирует свою обратную связь; во-вторых, LLM может такую обратную связь предоставить. Это аналогично итеративному процессу письма, через который проходит человек-писатель, доводя документ до готового вида.
Примеры, где evaluator-optimizer полезен:
- Литературный перевод, где есть нюансы, которые переводящая LLM может не уловить с первого раза, но где оценивающая LLM может дать полезные критические замечания.
- Сложные поисковые задачи, требующие нескольких раундов поиска и анализа для сбора всеобъемлющей информации, где оценивающая модель решает, нужны ли дальнейшие поиски.
Агенты
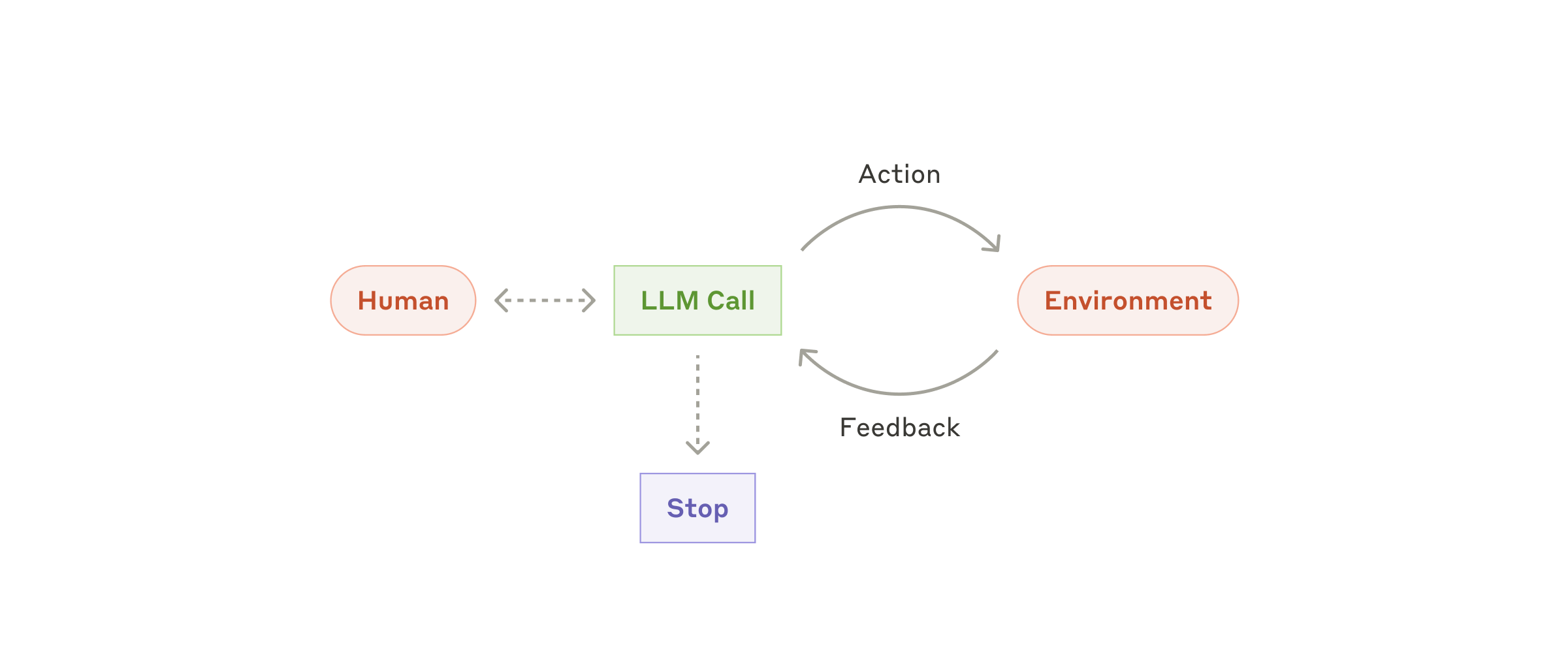
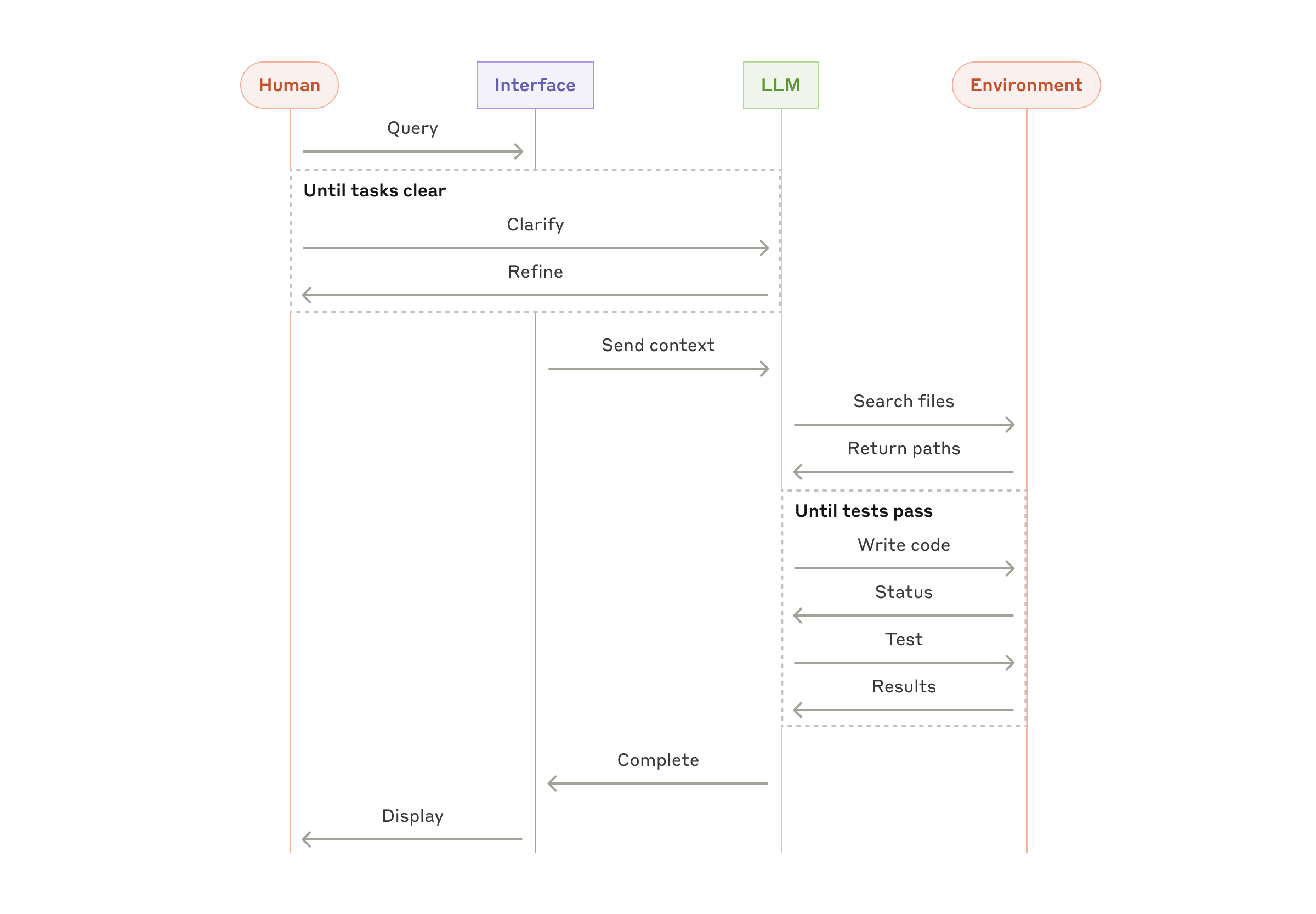
Агенты появляются в production по мере того, как LLM взрослеют в ключевых способностях — понимать сложные входные данные, рассуждать и планировать, надёжно использовать tools и восстанавливаться после ошибок. Агенты начинают работу либо с команды от пользователя, либо с интерактивного обсуждения с ним. Как только задача ясна, агенты планируют и работают независимо, потенциально возвращаясь к человеку за дополнительной информацией или суждением. Во время выполнения агенту критически важно получать «ground truth» из окружения на каждом шаге (например, результаты вызова tools или исполнения кода), чтобы оценивать свой прогресс. После этого агенты могут приостанавливаться для обратной связи от человека на контрольных точках или при столкновении с препятствиями. Задача часто завершается по выполнении, но также часто включают условия остановки (например, максимальное число итераций), чтобы сохранять контроль.
Агенты могут справляться со сложными задачами, но их реализация часто прямолинейна. Обычно это просто LLM, использующие tools на основе обратной связи от окружения в цикле. Поэтому критически важно проектировать наборы tools и их документацию ясно и продуманно. Лучшие практики разработки tools мы раскрываем в Приложении 2 («Prompt engineering для ваших tools»).
Когда использовать агентов: агентов можно использовать для открытых задач, в которых трудно или невозможно предсказать необходимое число шагов и в которых нельзя зашить фиксированный путь. LLM потенциально будет работать много ходов, и у вас должен быть некоторый уровень доверия к её принятию решений. Автономия агентов делает их идеальными для масштабирования задач в доверенных средах.
Автономная природа агентов означает более высокие затраты и потенциал накапливающихся ошибок. Мы рекомендуем всестороннее тестирование в sandbox-окружениях, наряду с подходящими guardrails.
Примеры, где агенты полезны:
Следующие примеры — из наших собственных реализаций:
- Coding-агент для решения задач SWE-bench, которые включают правки во многих файлах на основе описания задачи;
- Наша эталонная реализация «computer use», в которой Claude использует компьютер для решения задач.
Комбинирование и кастомизация этих паттернов
Эти строительные блоки — не предписание. Это общие паттерны, которые разработчики могут формовать и комбинировать под разные сценарии использования. Ключ к успеху, как и с любыми возможностями LLM, — оценивать результативность и итерировать реализацию. Повторим: добавлять сложность стоит только тогда, когда это наглядно улучшает результаты.
Итог
Успех в пространстве LLM не в том, чтобы построить самую сложную систему. Он в том, чтобы построить правильную систему под ваши нужды. Начинайте с простых prompts, оптимизируйте их через всестороннее оценивание и добавляйте многошаговые агентные системы, только когда более простых решений не хватает.
Реализуя агентов, мы стараемся следовать трём ключевым принципам:
- Сохраняйте простоту в дизайне вашего агента.
- Расставляйте приоритет на прозрачности, явно показывая шаги планирования агента.
- Аккуратно проектируйте интерфейс агент-компьютер (ACI) через тщательную документацию и тестирование tools.
Фреймворки могут помочь быстро стартовать, но не стесняйтесь сокращать слои абстракции и строить на базовых компонентах по мере выхода в production. Следуя этим принципам, вы можете создавать агентов, которые не только мощные, но и надёжные, поддерживаемые и которым доверяют пользователи.
Благодарности
Написано Эриком С. и Барри Чжаном. Эта работа опирается на наш опыт построения агентов в Anthropic и ценные инсайты, которыми поделились наши клиенты, — за что мы глубоко благодарны.
Приложение 1: агенты на практике
Наша работа с клиентами выявила два особенно перспективных применения для AI-агентов, которые демонстрируют практическую ценность обсуждённых выше паттернов. Оба применения иллюстрируют, как агенты дают наибольшую ценность для задач, которые требуют и разговора, и действия, имеют чёткие критерии успеха, поддерживают петли обратной связи и интегрируют осмысленный человеческий контроль.
A. Клиентская поддержка
Клиентская поддержка сочетает привычные интерфейсы чат-ботов с расширенными возможностями через интеграцию tools. Это естественный кандидат для более открытых агентов, потому что:
- Взаимодействия в поддержке естественно идут по разговорному потоку, при этом требуя доступа к внешней информации и действиям;
- Tools можно интегрировать, чтобы вытягивать данные о клиенте, историю заказов и статьи базы знаний;
- Действия вроде оформления возвратов или обновления тикетов можно обрабатывать программно;
- Успех можно чётко измерять через определяемые пользователем критерии решённости обращений.
Несколько компаний продемонстрировали жизнеспособность такого подхода через модели ценообразования по факту использования, в которых берут плату только за успешно решённые обращения, — это показывает уверенность в эффективности их агентов.
B. Coding-агенты
Пространство разработки ПО показало замечательный потенциал для возможностей LLM: способности эволюционировали от code completion до автономного решения проблем. Агенты особенно эффективны, потому что:
- Кодовые решения проверяемы автоматизированными тестами;
- Агенты могут итерировать решения, используя результаты тестов как обратную связь;
- Пространство задач хорошо определено и структурировано;
- Качество выходных данных можно измерить объективно.
В нашей собственной реализации агенты теперь могут решать реальные задачи GitHub в бенчмарке SWE-bench Verified, опираясь только на описание pull request. Однако, хотя автоматизированное тестирование помогает проверить функциональность, человеческое ревью остаётся критически важным для обеспечения соответствия решений более широким требованиям системы.
Приложение 2: prompt engineering для ваших tools
Какую бы агентную систему вы ни строили, tools, скорее всего, будут её важной частью. Tools позволяют Claude взаимодействовать с внешними сервисами и API, задавая их точную структуру и определение в нашем API. Когда Claude отвечает, он включает в API-ответ блок tool use, если планирует вызвать tool. Определениям и спецификациям tools нужно уделять не меньше внимания в prompt engineering, чем вашим общим prompts. В этом коротком приложении мы описываем, как делать prompt engineering для ваших tools.
Часто есть несколько способов задать одно и то же действие. Например, правку файла можно задать, написав diff, либо переписав файл целиком. Для структурированного вывода можно вернуть код внутри markdown или внутри JSON. В разработке ПО такие различия косметические и могут переводиться без потерь из одного формата в другой. Однако некоторые форматы LLM писать гораздо сложнее, чем другие. Чтобы написать diff, нужно знать, сколько строк меняется, в заголовке чанка ещё до того, как написан новый код. Чтобы писать код внутри JSON (по сравнению с markdown), нужно дополнительно экранировать переводы строк и кавычки.
Наши предложения по выбору форматов tools такие:
- Дайте модели достаточно токенов, чтобы «подумать», прежде чем она загонит себя в угол.
- Держите формат близким к тому, что модель видела как естественно встречающееся в текстах в интернете.
- Убедитесь, что нет форматных «накладных расходов» — например, необходимости держать точный счёт тысячам строк кода или экранировать строки в любом коде, который она пишет.
Эмпирическое правило — подумать, сколько усилий уходит на интерфейсы человек-компьютер (HCI), и запланировать столько же усилий на создание хороших интерфейсов агент-компьютер (ACI). Несколько мыслей о том, как это делать:
- Поставьте себя на место модели. Очевидно ли, как использовать этот tool, по описанию и параметрам, или вам пришлось бы тщательно подумать? Если так, то, вероятно, и для модели тоже. Хорошее определение tool часто включает примеры использования, граничные случаи, требования к формату входа и чёткие границы относительно других tools.
- Как можно изменить имена параметров или описания, чтобы сделать вещи более очевидными? Думайте об этом как о написании отличного docstring для джуниора-разработчика в вашей команде. Это особенно важно при использовании множества похожих tools.
- Тестируйте, как модель использует ваши tools: прогоняйте много примерных входов в нашем workbench, чтобы посмотреть, какие ошибки делает модель, и итерируйте.
- Применяйте poka-yoke к своим tools. Меняйте аргументы так, чтобы было сложнее ошибиться.
Создавая нашего агента для SWE-bench, мы фактически потратили больше времени на оптимизацию tools, чем на общий prompt. Например, мы обнаружили, что модель ошибалась с tools, использующими относительные пути к файлам, после того как агент уходил из корневого каталога. Чтобы это починить, мы изменили tool, чтобы он всегда требовал абсолютные пути к файлам, — и обнаружили, что модель использовала этот метод безошибочно.